
The dangerous middle#
The SAE defined six levels of driving automation in 2014. The framework has become famous less for what it prescribes than for what it reveals: a phase change buried in the middle of the scale.
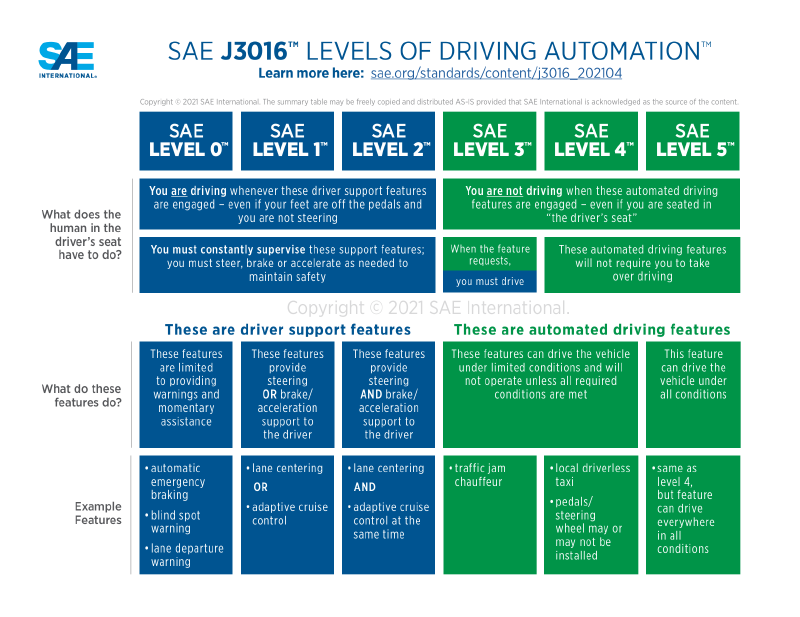
Source: SAE International J3016
At Levels 0 through 2, the human drives. The system helps: lane keeping, adaptive cruise, etc., but the human performs tasks and monitors the environment. At Level 3, the system performs tasks and the human is expected to be available as a fallback, ready to intervene when called upon. On paper, it’s just the next step in the journey, but in practice, it is a fundamental change in who is responsible for what. Over a decade of automotive safety research since the standard’s introduction has shown that this middle zone, where the system is capable enough to disengage the human but not capable enough to be safe alone, is where the worst outcomes concentrate.
AI coding agents crossed from Level 2 to Level 3 around November of 2025.
Level 2 was autocomplete. Copilot suggesting the next line, the developer accepting or rejecting, the human always in control of what executes. Level 3 is agents that run shell commands, make network requests, edit files across repositories, and orchestrate multi-step workflows. The agent performs the task. The developer reviews. Sometimes. Frameworks like OpenClaw push further toward full task autonomy.
The parallel holds uncomfortably well. When agents went from suggesting code to executing it, the environment didn’t noticably change. Same terminal. Same filesystem. Same credentials. Same network. The autonomy level shifted, but the infrastructure stayed exactly where it was, just like a driver whose car now steers itself on roads that were designed for human drivers.
The tool makers acknowledge this, and they’ve added permission prompts, approval gates, --yolo flags you have to
explicitly opt into. These are the “keep your hands on the wheel” warnings of coding agents, and like every driver who’s
been glancing at their phone for “just a moment”, developers ignore them. Not because they’re reckless, but because
Level 2 friction applied to Level 3 autonomy is intolerable. The human stops being meaningfully in the loop long before
they stop clicking “approve.”
This has a name. Norm Hardy described it in 1988: the confused deputy problem. A program acting with authority it shouldn’t be exercising on someone else’s behalf. A Fortran compiler on a Tymshare box. An AI agent with your SSH keys. The details change; the structure doesn’t. We’ve built the most confused, most enthusiastic deputy in the history of computing, and we’ve handed it the keys to production.
The industry response so far has been, largely, to talk about it. Approval gates, trust tiers, audit trails, etc. All important ideas. All discussed at length. Deployed? Rarely, and usually partially. Simon Willison has written about this pattern: the slow normalization of practices that everyone knows are unsafe but nobody stops doing because nothing has gone catastrophically wrong yet.
If you accept that agents are running untrusted code with real credentials, and you accept that the guardrails are mostly aspirational, then the question becomes: what would a meaningful guardrail even look like?
The fox guarding the henhouse#
The governance conversation tends to focus on constraining what the agent does. Don’t leak credentials. Don’t install arbitrary packages. Don’t modify governance files. Whether the enforcement is the agent’s own instructions, a multi-agent quorum, or even the existing tool permission systems built into many agent harnesses, the agent still possesses the secret. The evaluator constrains what the agent does, not what the agent knows.
This is the fox guarding the henhouse. If the agent possesses the secret, the secret can be exfiltrated. You are one prompt injection or malicious dependency away from exposure.
This isn’t a new problem. Solaris Zones, FreeBSD jails, and Linux cgroups solved it decades ago. The process inside the jail doesn’t get to decide what the jail allows. The enforcement is structural, not behavioral.
If the agent never possesses the secret, the secret cannot be exfiltrated. Not because you told the agent not to leak it, but because the secret does not exist inside the execution boundary.
An approach to sandboxing#
I’ve been impressed by the approach taken by Gondolin, an open-source project that runs code inside local, disposable micro-VMs with programmable network and filesystem control. It is designed for exactly this scenario: an AI agent needs to run generated code, and you need that code to not be able to reach things it shouldn’t.
Three properties stand out:
Secret injection without guest exposure. The guest gets a placeholder token. The host-side proxy substitutes the
real credential, but only for requests to explicitly allowlisted destinations. Your agent can curl all day. It’s not
sending your GitHub token anywhere you haven’t approved, because the agent doesn’t have your GitHub token. The token
never existed inside the VM.
Programmable network egress. Every outbound connection from the VM goes through a userspace network stack on the host. HTTP and TLS traffic is intercepted, classified, and either forwarded or blocked based on a hostname allowlist. Unmapped TCP is rejected, redirects are followed and re-validated host-side to prevent policy escapes, and in the default DNS mode, the guest gets synthetic responses rather than real upstream resolution. The enforcement happens before any real socket is created.
Programmable filesystem mounts. Gondolin’s VFS layer lets you write custom filesystem behavior in JavaScript and
mount it into the VM. A project directory can be mounted read-write for the agent’s work, while sensitive files
(.env, .npmrc) are hidden via a shadow mount that makes them invisible to the guest. More importantly for
governance: you can mount an agent’s charter, routing rules, or system prompt as a read-only overlay. The agent can read
its instructions but it cannot rewrite them; not because you asked nicely, because the mount is read-only and the agent
doesn’t control the mount table.
Does it actually work for real workloads?#
I wanted to find out. So I took a realistic .NET developer workload and tried to run it inside a Gondolin sandbox: an Aspire AppHost that orchestrates Docker containers, serves a dashboard, and pulls container images from Docker Hub.
This exercises the full stack: .NET SDK, NuGet restore through an HTTPS-intercepting proxy, Docker image pulls through the same proxy, Kestrel serving HTTP, and container orchestration via Aspire’s DCP. If the sandbox breaks any of these, it’s not viable for real work.
The whole thing runs end-to-end. The Aspire dashboard is accessible from the host through Gondolin’s ingress gateway. The nginx container pulls through the MITM proxy, starts via Aspire’s DCP, and responds to requests routed through a prefix-based ingress rule. NuGet autodetects the Alpine runtime and restores the correct platform-specific packages.1
Getting there required the usual infrastructure work: building a custom VM image with the right packages, sizing the VM appropriately, configuring the network allowlist for Docker Hub’s surprisingly complex redirect chain, and mounting a persistent NuGet cache so packages don’t re-download on every VM boot. A follow-up post walks through the full setup.
Start with the thing that doesn’t require trust#
Every team running AI agents today is making a choice, whether they realize it or not. The choice is between “we try to convince the agent to behave” and “we’ve made it so the agent doesn’t have to behave in order to be safe.” The gap between these two postures grows with every new capability we hand to agents.
The tooling exists today. The concepts underneath it, VM-based isolation, network mediation, secret injection, are well-understood infrastructure patterns from decades of systems work. None of this is speculative.
What’s missing is adoption. People are waiting for their cloud provider to ship a managed service, or for their agent framework to add a “sandbox mode” checkbox (some already do). Simon Willison’s normalization of deviance again: nothing has gone wrong yet, so the current posture feels fine. It’s not fine. It’s just lucky.
I’d rather have both the sandbox and the governance layer. But if I have to pick a first step, I’m starting with the thing that doesn’t require trust.

